Guido SalimbeniI got my App online… and a database.How to publish a web application using React and connect to a MySQL database using a PHP file as a backend.Apr 15, 2022Apr 15, 2022
Guido SalimbeniAVACAArtificial Intelligence Game for Still Life Composition. AVACA is a made-up name for a game available for free on Google Play, which is…Jun 21, 2021Jun 21, 2021
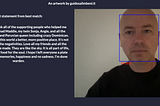
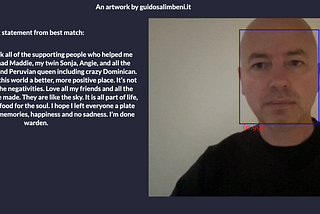
Guido SalimbeniFace Similarity in ReactMy Khe Nguyen provided to the Kaggle community a dataset that has the last words of death row inmates. The data contains information on…Jun 20, 2021Jun 20, 2021
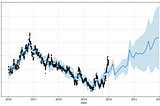
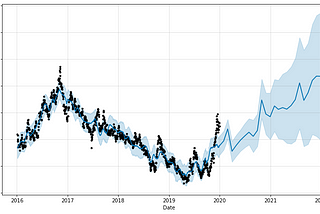
Guido SalimbeniDay Three in Machine Learning: web scraping and multivariate future predictions with Prophet.This article is about Machine Learning prediction using data collected from a website and google trend. It is a toy example that assumes a…Jan 16, 2021Jan 16, 2021
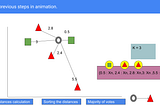
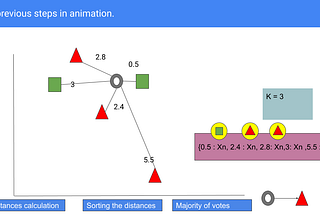
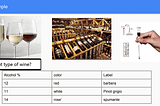
Guido SalimbeniinAnalytics VidhyaDay two in Machine Learning: KNNBuild a K-nearest Neighbors from scratch in Python and theory.Jan 8, 2021Jan 8, 2021
Guido SalimbeniinThe StartupDay One in Machine LearningThe whole concept of machine learning is figuring out ways in which we can teach a computer to perform a task without needing to provide…Jan 5, 2021Jan 5, 2021